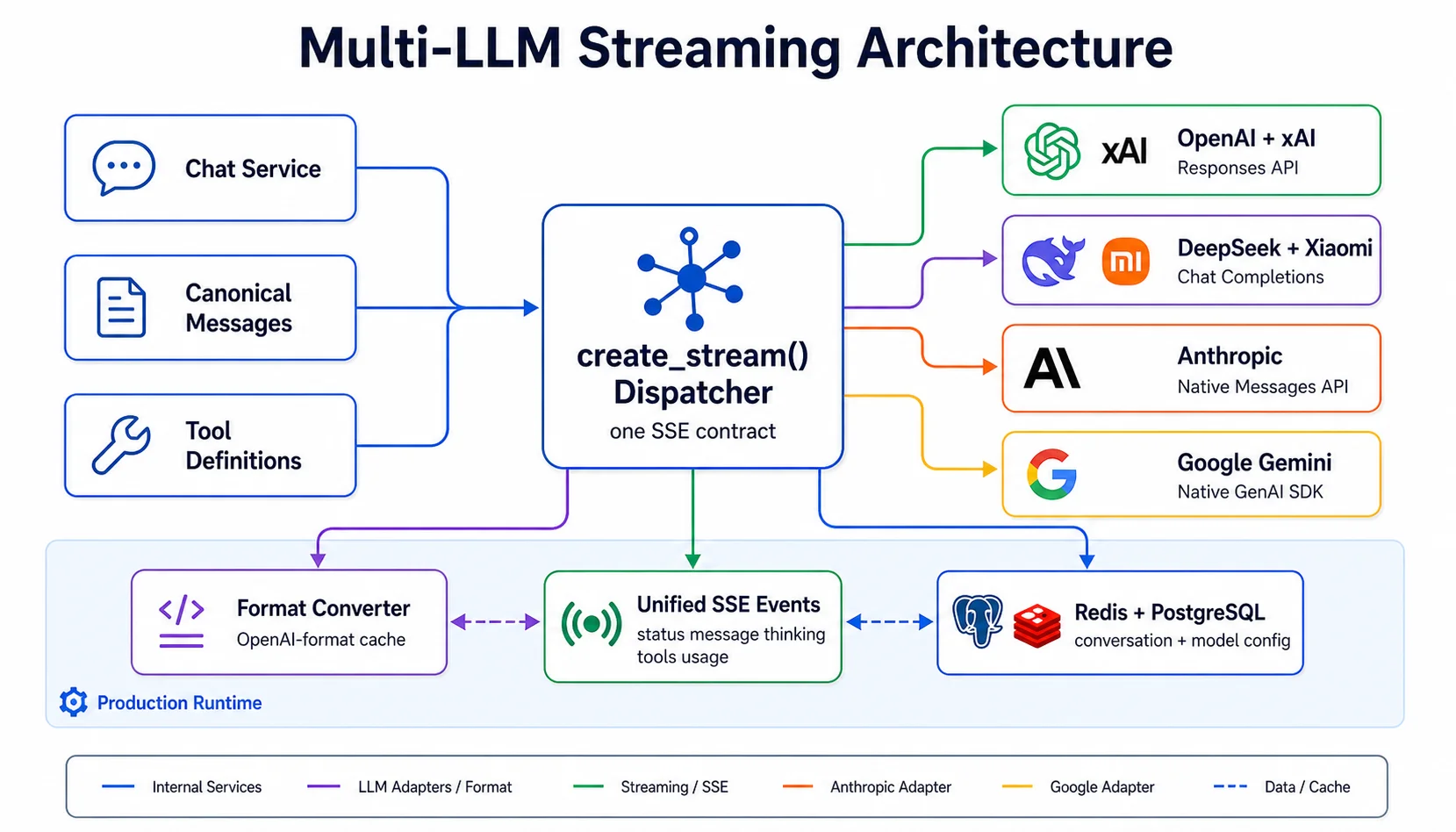
Khi xây dựng AI product nghiêm túc, câu hỏi không phải "dùng model nào?" mà là "làm sao để dùng được TẤT CẢ model?" — vì mỗi provider có thế mạnh riêng, giá khác nhau, và landscape thay đổi liên tục.
Bài viết này giải thích cách chúng tôi thiết kế kiến trúc multi-LLM trong Assistant Core — từ native SDK integration đến prompt caching strategy giúp tiết kiệm 90% chi phí input token.
Tại sao cần Multi-LLM?
Không có model nào "tốt nhất" cho mọi tác vụ. Thực tế triển khai cho thấy:
- GPT-5.4 mạnh về reasoning phức tạp nhưng $15/1M output token — quá đắt cho FAQ
- Gemini 3.5 Flash nhanh và hỗ trợ video/audio native nhưng đôi khi yếu hơn ở tool calling phức tạp
- Claude Sonnet 4.6 xuất sắc cho code và agentic workflows với extended thinking, nhưng không hỗ trợ audio/video
- DeepSeek V4 Flash chỉ $0.14/1M input — rẻ nhất thị trường với chất lượng MoE ấn tượng
- Grok 4.3 từ xAI mạnh về realtime voice và reasoning
- MiMo V2.5 từ Xiaomi — economy model với chất lượng ấn tượng, miễn phí
Nếu chỉ dùng 1 provider, bạn bị vendor lock-in — khi provider gặp sự cố hoặc tăng giá, toàn bộ hệ thống bị ảnh hưởng.
Bức tranh model hiện tại (06/2026)
Platform hiện hỗ trợ 14 model LLM từ 6 provider:
| Provider | Model | Input Cost | Output Cost | Context |
|---|---|---|---|---|
| OpenAI | GPT-5.4 | $2.50 | $15.00 | 1.05M |
| OpenAI | GPT-5.4 Mini | $0.75 | $4.50 | 400K |
| OpenAI | GPT-4.1 | $2.00 | $8.00 | 1M |
| OpenAI | GPT-4.1 Mini | $0.40 | $1.60 | 1M |
| Anthropic | Claude Sonnet 4.6 | $3.00 | $15.00 | 1M |
| Anthropic | Claude Haiku 4.5 | $1.00 | $5.00 | 200K |
| Gemini 3.5 Flash | $1.50 | $9.00 | 1M | |
| Gemini 3.1 Flash Lite | $0.30 | $2.50 | 1M | |
| xAI | Grok 4.3 | $1.25 | $2.50 | 1M |
| DeepSeek | V4 Pro | $0.435 | $0.87 | 1M |
| DeepSeek | V4 Flash | $0.14 | $0.28 | 1M |
| Xiaomi | MiMo V2.5 | Miễn phí | Miễn phí | 128K |
| Xiaomi | MiMo V2.5 Pro | $0.07 | $0.28 | 128K |
Chi phí dao động hơn 100 lần (MiMo V2.5 miễn phí → GPT-5.4 $15.00 per 1M output). Việc chọn đúng model cho đúng tác vụ ảnh hưởng trực tiếp đến chi phí vận hành.
Kiến trúc Native SDK — Không dùng Abstraction Layer
Một quyết định quan trọng: chúng tôi không dùng LangChain hay bất kỳ abstraction layer nào. Mỗi provider sử dụng native SDK riêng.
Tại sao? Vì abstraction layers luôn bị tụt phía sau provider updates. Khi Anthropic ra prompt caching, khi Gemini thêm thinking mode, khi OpenAI thêm reasoning effort — abstraction layer cần thời gian cập nhật. Native SDK cho phép chúng tôi dùng feature mới ngay lập tức.
# LLMManager — Factory tạo native SDK client cho từng provider
class LLMManager:
async def get_llm_instance(self, model, assistant_id):
provider_code = model.provider.provider_code
# OpenAI-compatible providers (OpenAI, xAI, DeepSeek)
if provider_code in (ProviderCode.OPENAI, ProviderCode.XAI, ProviderCode.DEEPSEEK):
return AsyncOpenAI(api_key=api_key, base_url=base_url), config
# Anthropic — native SDK
if provider_code == ProviderCode.ANTHROPIC:
return AsyncAnthropic(api_key=api_key), config
# Google — native google-genai SDK
if provider_code == ProviderCode.GOOGLE:
return genai.Client(api_key=api_key), config
Kiến trúc này có 3 SDK clients phục vụ 6 providers:
AsyncOpenAI— OpenAI, xAI (base_urlapi.x.ai), DeepSeek (base_urlapi.deepseek.com), Xiaomi (base_urlapi.xiaomi.com)AsyncAnthropic— Anthropicgenai.Client— Google (Gemini)
Bộ Phân Phối Streaming — create_stream()
Trung tâm kiến trúc là một dispatcher function duy nhất quyết định gọi streaming function nào:
def create_stream(client, config, messages, tools, ...):
"""Điểm vào duy nhất — ChatService chỉ gọi function này."""
if config.provider == ProviderCode.GOOGLE:
return stream_gemini_native(...)
elif config.provider == ProviderCode.ANTHROPIC:
return stream_anthropic_native(...)
else:
return stream_openai_compat(...) # OpenAI, xAI, DeepSeek
Mỗi streaming function yield SSE events theo format thống nhất:
{"event": "status", "content": "Generating response..."}
{"event": "message", "content": "Xin chào"} # Text delta
{"event": "thinking", "content": "Để tôi suy..."} # Reasoning delta
{"event": "aborted", "content": "Streaming aborted"}
Đổi Model Giữa Cuộc Trò Chuyện
Một tính năng mạnh: user có thể đang chat với GPT-5.4, chuyển sang Claude Sonnet 4.6 giữa cuộc hội thoại, và Claude tiếp tục trả lời với đầy đủ context trước đó.
Bí quyết là Canonical Message Format: tất cả message được lưu trong Redis theo format chuẩn OpenAI.
# Format chuẩn lưu trong Redis — bất kể provider nào tạo ra
{"role": "system", "content": "Bạn là assistant hữu ích..."}
{"role": "user", "content": "Phân tích tài liệu này"}
{"role": "assistant", "content": "Dựa trên tài liệu...", "tool_calls": [...]}
{"role": "tool", "tool_call_id": "call_123", "content": "kết quả"}
Khi user đổi model, format_converter.py tự động chuyển đổi:
- OpenAI → Anthropic: system prompt tách riêng,
role: "tool"→role: "user"vớitype: "tool_result", image format conversion - OpenAI → Gemini: tạo
types.Contentobjects,FunctionCall/FunctionResponse, stripadditionalProperties(Gemini không hỗ trợ)
Prompt Caching — Tiết kiệm 90% Chi Phí Input
Đây là optimization có impact lớn nhất đến chi phí vận hành. Mỗi provider có cơ chế riêng:
Anthropic — Chiến lược 3 Breakpoints
Anthropic cho phép cache tường minh bằng cache_control markers. Platform sử dụng 3 trong 4 slots cho phép:
# Breakpoint 1 — System prompt (ít thay đổi)
create_kwargs["system"] = [{
"type": "text",
"text": system_prompt,
"cache_control": {"type": "ephemeral"}, # Cache 5 phút
}]
# Breakpoint 2 — Tool definitions (ít thay đổi)
tools[-1]["cache_control"] = {"type": "ephemeral"}
# Breakpoint 3 — Automatic caching (conversation history)
create_kwargs["cache_control"] = {"type": "ephemeral"}
# Auto-đặt breakpoint ở block cuối, tự dịch forward khi conversation dài ra
Kết quả đo được:
| Lượt | Cache Creation | Cache Read | Input mới | Phân tích |
|---|---|---|---|---|
| 1 — Seed | 2,128 | 0 | 408 | Tạo cache lần đầu |
| 2 — Hit | 831 | 2,128 | 658 | Prefix cache hit ✅ |
| 3 — Growing | 167 | 1,075 | 1,258 | Auto-breakpoint dịch forward |
Với automatic caching, input_tokens giảm xuống chỉ 10–11 tokens — toàn bộ prefix được phục vụ từ cache với 90% giảm giá.
OpenAI — Cache Tự Động
OpenAI cache tự động khi prompt vượt 1,024 tokens — không cần cấu hình gì:
# Kiểm tra cache qua usage metadata
cached_tokens = chunk.usage.prompt_tokens_details.cached_tokens
# Cache read: 50% discount trên input cost
Gemini — Implicit Caching
Gemini tự động cache qua cached_content_token_count — hoàn toàn implicit, không cần breakpoints.
Tính Năng Đặc Thù Theo Provider
Kiến trúc native SDK cho phép khai thác feature riêng của từng provider:
| Tính năng | OpenAI | Anthropic | Gemini | DeepSeek |
|---|---|---|---|---|
| Reasoning mode | reasoning_effort | thinking_budget | ThinkingConfig | reasoning_content |
| Prompt caching | Tự động (50%) | Tường minh (90%) | Implicit | Tự động |
| Audio/Video input | ❌ | ❌ | ✅ Native | ❌ |
| Tool calling | Parallel ✅ | Sequential | Sequential | Parallel ✅ |
| Observability | LangSmith ✅ | LangSmith ✅ | ❌ | LangSmith ✅ |
Hot-Reload Model — Zero Downtime
Admin có thể đổi model trên dashboard mà không cần restart server. Model config lưu trong database, LLMManager tạo client dynamically theo config hiện tại của assistant.
# Mỗi request, LLMManager tạo client mới dựa trên model trong DB
client, config = await llm_manager.get_llm_instance(
model=assistant.current_model, # Đọc từ DB real-time
assistant_id=assistant.id,
)
# API key resolution: assistant-specific (KMS decrypt) → env default
# Cho phép mỗi assistant dùng API key riêng
Điều này cũng hỗ trợ multi-tenancy: mỗi assistant (mỗi doanh nghiệp) có thể dùng model stack, API key, và cấu hình riêng.
Heuristic Chọn Model
Từ kinh nghiệm triển khai thực tế, đây là heuristic đơn giản:
- Bắt đầu với DeepSeek V4 Flash ($0.14/1M input) — rẻ nhất thị trường, chất lượng MoE ấn tượng, lý tưởng làm default model
- Upgrade lên Claude Sonnet 4.6 khi cần code generation, agentic workflows, hoặc extended thinking mạnh
- Thêm GPT-5.4 cho tác vụ multimodal phức tạp hoặc reasoning frontier
- MiMo V2.5 cho economy tier — miễn phí, chất lượng tốt cho các tác vụ đơn giản
- Gemini 3.5 Flash cho premium mid-tier — $1.50/1M input, 1M context, thinking mode sẵn
Và rule quan trọng nhất: luôn bật prompt caching. Đây là optimization có ROI cao nhất — implementation một lần, tiết kiệm mỗi request.